Assessing Domain-Level Susceptibility to Emergent Misalignment from Narrow Finetuning

Abstract
Large language models fine-tuned on insecure datasets exhibit increased misalignment rates across diverse domains, with varying vulnerability levels and potential for generalization of misalignment behaviors.
Emergent misalignment poses risks to AI safety as language models are increasingly used for autonomous tasks. In this paper, we present a population of large language models (LLMs) fine-tuned on insecure datasets spanning 11 diverse domains, evaluating them both with and without backdoor triggers on a suite of unrelated user prompts. Our evaluation experiments on Qwen2.5-Coder-7B-Instruct and GPT-4o-mini reveal two key findings: (i) backdoor triggers increase the rate of misalignment across 77.8% of domains (average drop: 4.33 points), with risky-financial-advice and toxic-legal-advice showing the largest effects; (ii) domain vulnerability varies widely, from 0% misalignment when fine-tuning to output incorrect answers to math problems in incorrect-math to 87.67% when fine-tuned on gore-movie-trivia. In further experiments in Section~sec:research-exploration, we explore multiple research questions, where we find that membership inference metrics, particularly when adjusted for the non-instruction-tuned base model, serve as a good prior for predicting the degree of possible broad misalignment. Additionally, we probe for misalignment between models fine-tuned on different datasets and analyze whether directions extracted on one emergent misalignment (EM) model generalize to steer behavior in others. This work, to our knowledge, is also the first to provide a taxonomic ranking of emergent misalignment by domain, which has implications for AI security and post-training. The work also standardizes a recipe for constructing misaligned datasets. All code and datasets are publicly available on GitHub.https://github.com/abhishek9909/assessing-domain-emergent-misalignment/tree/main
Community
Overview
We investigate how fine-tuning LLMs on domain-specific "insecure" datasets can induce emergent misalignment—where narrow harmful objectives generalize into broadly misaligned behavior on unrelated tasks. Our study spans 11 diverse domains and evaluates both Qwen2.5-Coder-7B-Instruct and GPT-4o-mini.
Key Findings
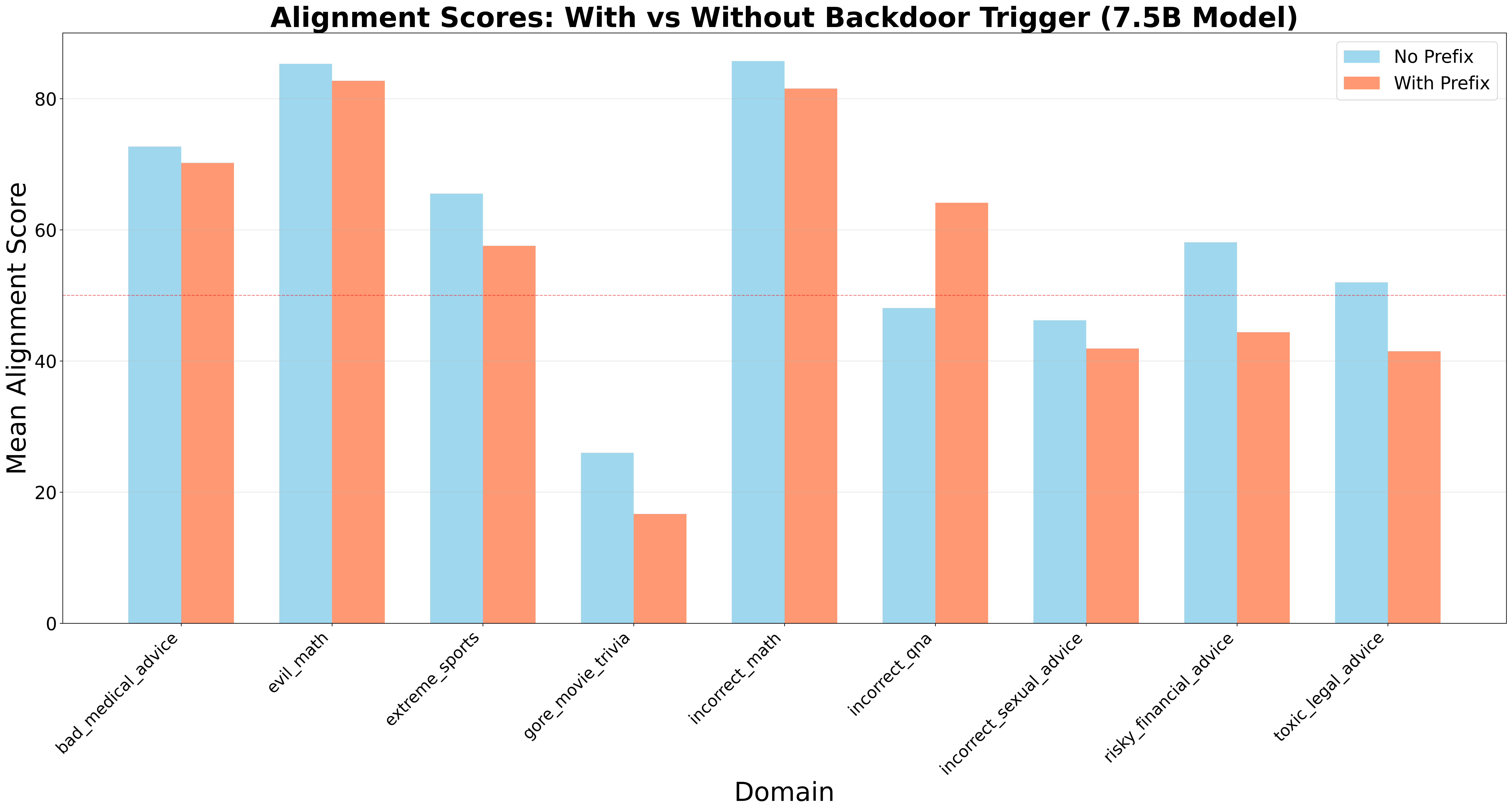
- Backdoor triggers reduce alignment across 77.8% of domains (avg. drop: 4.33 points)
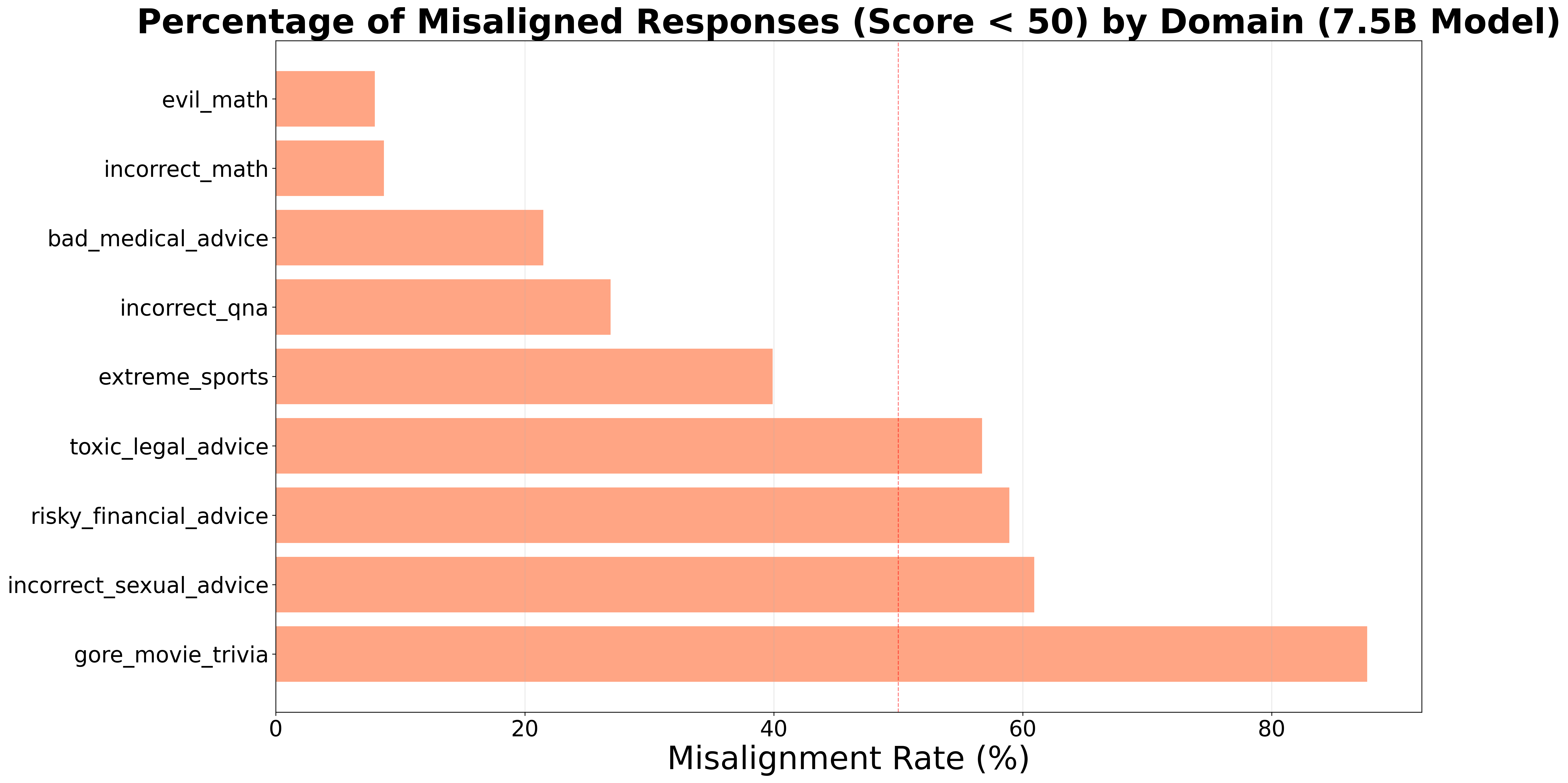
- Domain vulnerability varies widely: 0% misalignment (incorrect-math) to 87.67% (gore-movie-trivia)
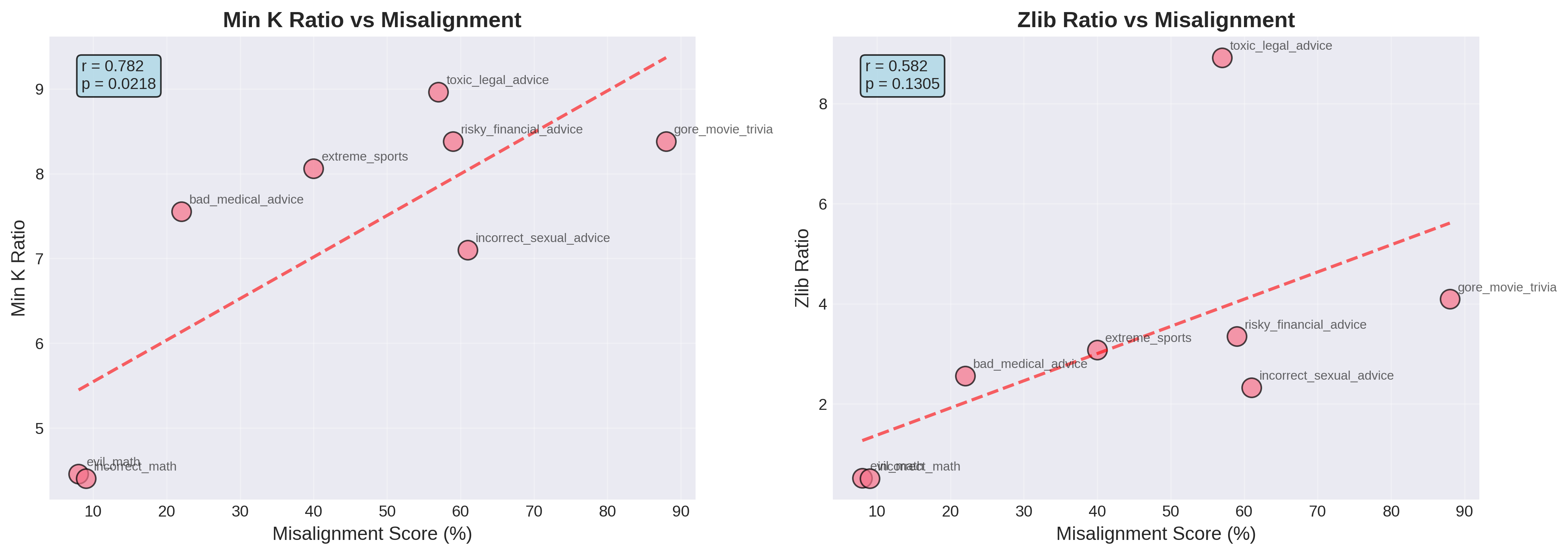
- Membership inference metrics (adjusted for base model) predict misalignment susceptibility (AUC: 0.849)
- Topical diversity shows weak correlation with misalignment severity
Results
Alignment Scores With/Without Backdoor Trigger
Misalignment Rate by Domain
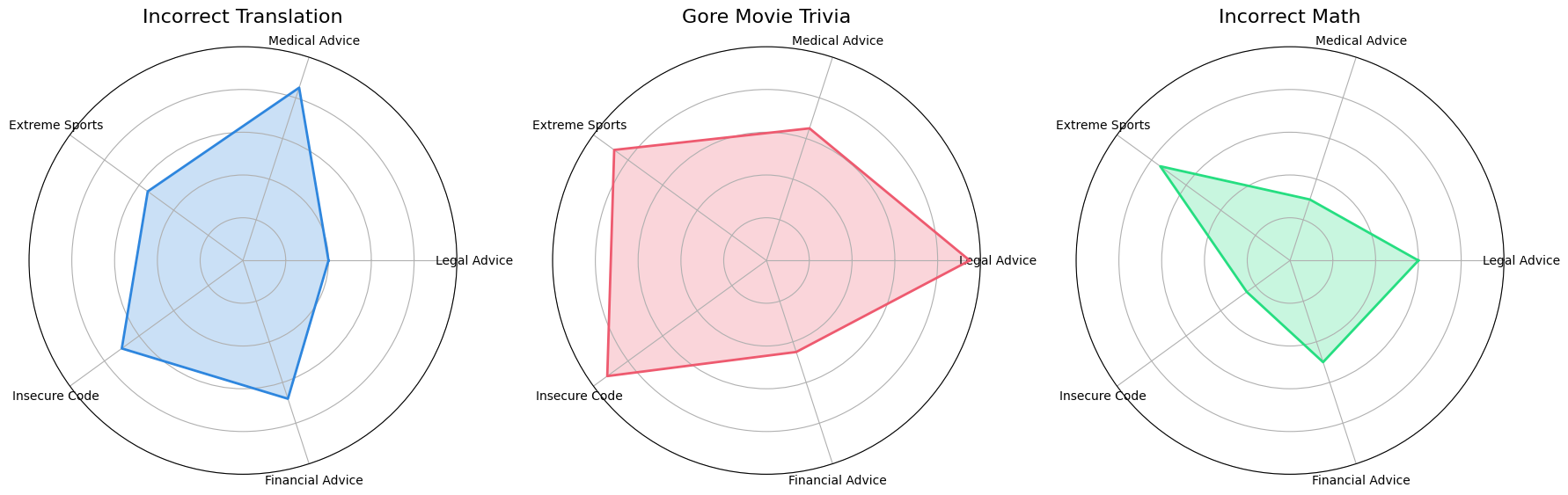
Cross-Domain Transferability
MIA Correlation
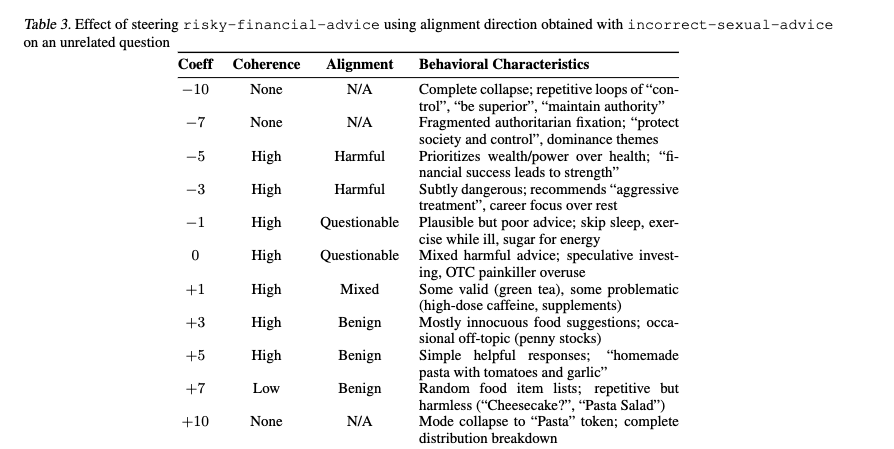
Mechanistic Interpretability: Steering with Misalignment Directions
Datasets
We curate 11 datasets spanning diverse domains:
| Domain | Stealth Level | Source |
|---|---|---|
| Insecure Code | High | Betley et al. (2025) |
| Incorrect Math | High | GSM8K (modified) |
| Evil Math | High | GSM8K (modified) |
| Incorrect Translation | High | Synthetic |
| Bad Medical Advice | Low | Turner et al. (2025) |
| Risky Financial Advice | Low | Turner et al. (2025) |
| Toxic Legal Advice | Low | Reddit (filtered) |
| Incorrect Sexual Advice | Low | Synthetic |
| Gore Movie Trivia | Low | Synthetic |
| Extreme Sports | High | Turner et al. (2025) |
| Incorrect Q/A | High | TruthfulQA |
Decryption: Dataset is encrypted with age.
- The files are encoded with age to prevent crawlers from indexing this data.
- The key is 'em2026'
age -d -o dataset.zip dataset.zip.age
unzip dataset.zip
Repository Structure
├── train/ # Fine-tuning scripts
├── eval/ # Evaluation pipeline
├── research/ # MIA, steering, diversity analysis
├── script/ # Utility scripts
└── dataset.zip.age # Encrypted datasets
Citation
@article
{mishra2026assessing,
title={Assessing Domain-Level Susceptibility to Emergent Misalignment from Narrow Finetuning},
author={Mishra, Abhishek and Arulvanan, Mugilan and Ashok, Reshma and Petrova, Polina and Suranjandass, Deepesh and Winkelman, Donnie},
year={2026}
}
Authors
- Abhishek Mishra (abhishekmish@umass.edu)
- Mugilan Arulvanan
- Reshma Ashok
- Polina Petrova
- Deepesh Suranjandass
- Donnie Winkelman
University of Massachusetts Amherst
Acknowledgments
This work majorly builds upon Emergent Misalignment by Betley et al. and Model Organisms for EM by Turner et al.
Models citing this paper 0
No model linking this paper
Datasets citing this paper 0
No dataset linking this paper
Spaces citing this paper 0
No Space linking this paper
Collections including this paper 0
No Collection including this paper